There is one more thing you will have to do:
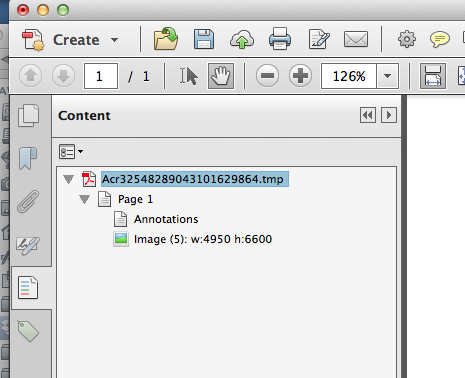
Have you seen the "Content" pane on the left side? Most users will never open this, but here is your chance to dig a little deeper into your PDF file :) Here is what the Contents pane will look like for a document that you just scanned, without doing any optimizations:
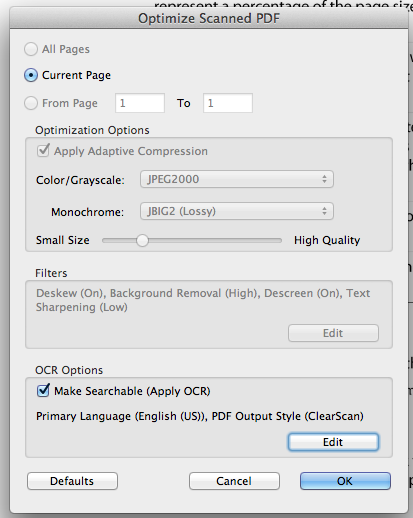
When you run the optimize scanned document function, select the ClearScan output format:
Once you've done, return to the Contents pane and expand the tree until you see the actual content, including the background image:
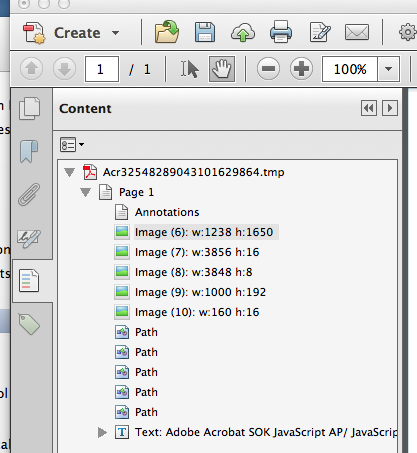
Highlight the first image and hit the delete key. This should get rid of the background. Now you an add your own background color. However, keep in mind that this will only work for text: Anything that is an image will retain it's white background color.
Karl Heinz Kremer
PDF Acrobatics Without a Net
PDF Software Development, Training and More...
http://www.khkonsulting.com